
Abstract
Existing segmentation models based on multimodal large language models (MLLMs), such as LISA, often struggle with novel or emerging entities due to their inability to incorporate up-to-date knowledge. To address this challenge, we introduce the Novel Emerging Segmentation Task (NEST), which focuses on segmenting (i) novel entities that MLLMs fail to recognize due to their absence from training data, and (ii) emerging entities that exist within the model's knowledge but demand up-to-date external information for accurate recognition. To support the study of NEST, we construct a NEST benchmark using an automated pipeline that generates news-related data samples for comprehensive evaluation. Additionally, we propose ROSE: Retrieval-Oriented Segmentation Enhancement, a plug-and-play framework designed to augment any MLLM-based segmentation model. ROSE comprises four key components. First, an Internet Retrieval-Augmented Generation module is introduced to employ user-provided multimodal inputs to retrieve real-time web information. Then, a Textual Prompt Enhancer enriches the model with up-to-date information and rich background knowledge, improving the model's perception ability for emerging entities. Furthermore, a Visual Prompt Enhancer is proposed to compensate for MLLMs' lack of exposure to novel entities by leveraging internet-sourced images. To maintain efficiency, a WebSense module is introduced to intelligently decide when to invoke retrieval mechanisms based on user input. Experimental results demonstrate that ROSE significantly boosts performance on the NEST benchmark, outperforming a strong Gemini-2.0 Flash-based retrieval baseline by 19.2% in gIoU.
NEST Data Engine
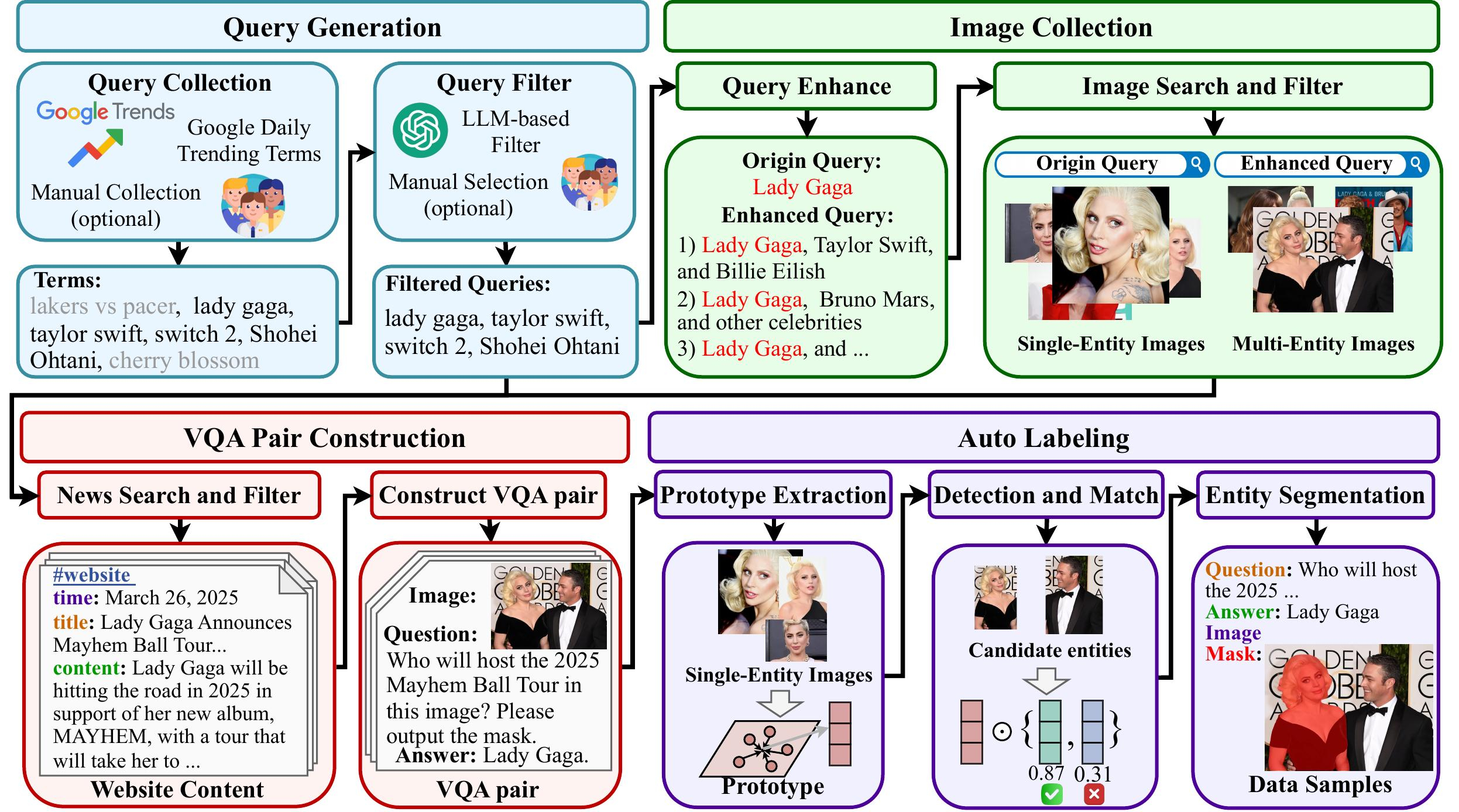
We introduce an automated annotation pipeline that efficiently generates high-quality evaluation samples for the novel emerging segmentation task. The pipeline leverages time-specific queries to continuously collect news content and corresponding relevant images for constructing VQA pairs and automatically generating mask annotations, enabling a comprehensive and reliable evaluation of models' abilities to segment emerging entities.
Architecture Overview
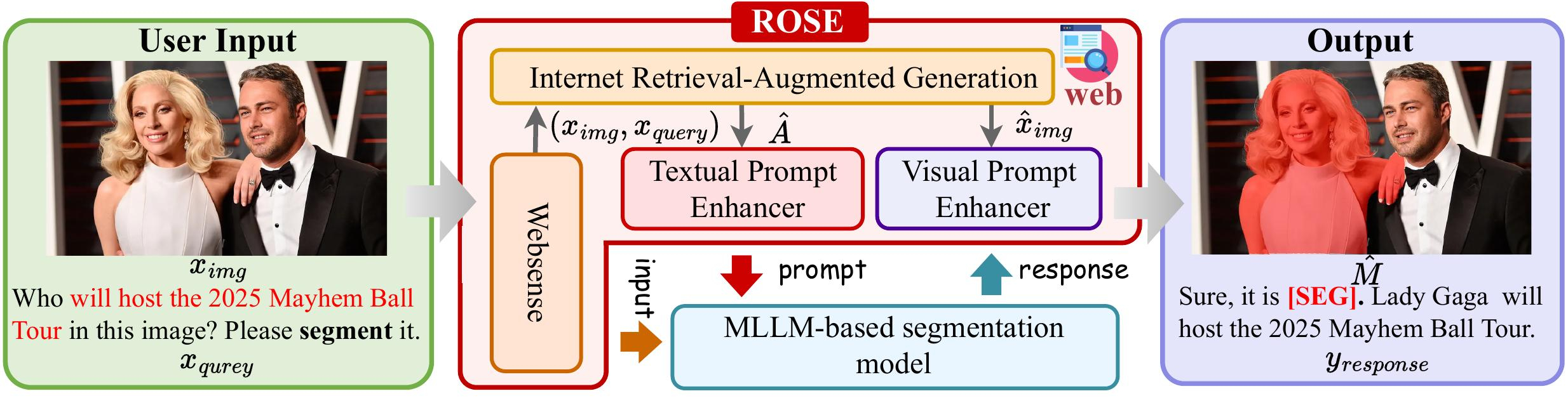
Given a user input (image and question), ROSE first employs the WebSense module to determine whether internet retrieval is needed. If so, the Internet Retrieval-Augmented Generation module retrieves relevant textual and visual data from the web. The retrieved content is then processed by the Textual and Visual Prompt Enhancer to generate enriched prompts for the MLLM-based segmentation model, which ultimately produces accurate segmentation masks for novel and emerging entities.
Qualitative Results

Qualitative results comparing LISA, READ, and ROSE (ours) on novel and emerging entities. ROSE accurately segments unseen and newly emerging targets, while existing MLLM-based segmentation models struggle due to outdated knowledge or limited exposure to novel entities.
BibTeX
@inproceedings{ROSE,
title={ROSE: Retrieval-Oriented Segmentation Enhancement},
author={Tang, Song and Jie, Guangquan and Ding, Henghui and Jiang, Yu-Gang},
booktitle={CVPR 2026 Findings},
year={2026}
}