Abstract
Recent layout-to-image models have achieved remarkable progress in spatial controllability. However, they still struggle with inter-object occlusion. When bounding boxes overlap, most existing methods lack explicit occlusion information, which makes the generation in intersection regions inherently ambiguous and hinders the determination of complex occlusion relationships. As a result, they often produce entangled textures or physically inconsistent layering in the overlapped areas. To address this issue, we first construct SA-Z, a large-scale dataset enriched with explicit occlusion ordering and pixel-level annotations. Building upon our proposed dataset, we introduce OcclusionFormer, a novel occlusion-aware Diffusion Transformer framework that explicitly models Z-order priority by decoupling instances and compositing them via volume rendering. Furthermore, to ensure fine-grained spatial precision, we introduce a queried alignment loss that explicitly supervises individual instances and enhances semantic consistency. The proposed method effectively reduces ambiguity in overlapping regions, enforces correct occlusion dependencies, and preserves structural integrity, leading to substantial accuracy gains across diverse scenes.

Challenges in Current Layout-Grounded Image Generation
Existing methods lack explicit, data-driven modeling of inter-object occlusion and Z-order, leading to ambiguous generation and physically inconsistent compositions. As a result, multiple plausible outcomes may exist for overlapping regions, yet current models lack the ability to control which outcome is produced.
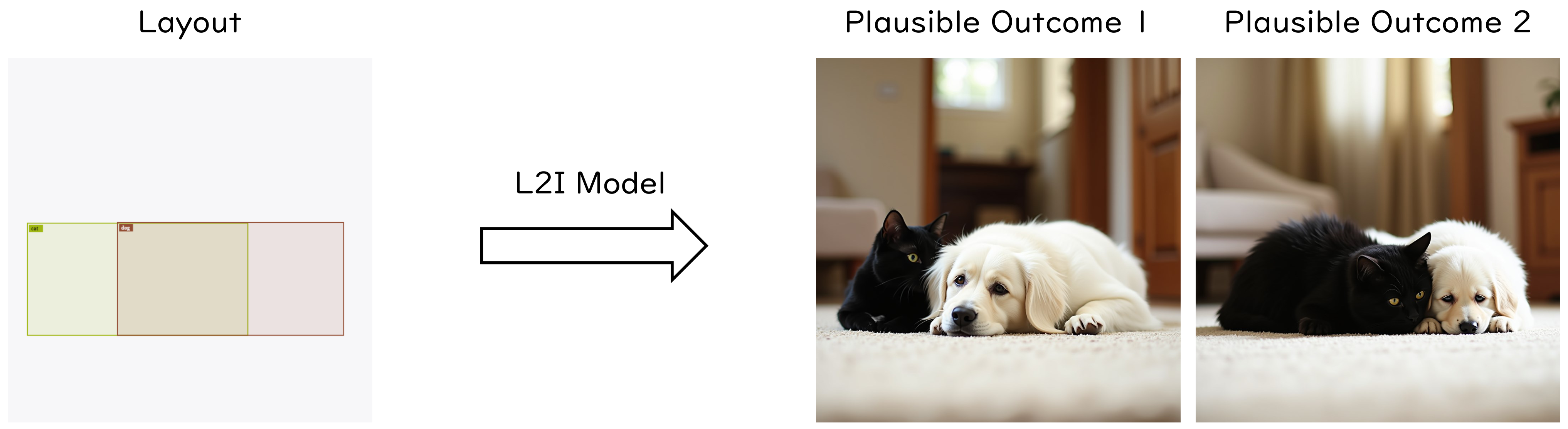
Our Sollution: OcclusionFormer
Each folder keeps the same bounding boxes fixed. Use the slider in each card to switch between Z-order examples.
Methodology
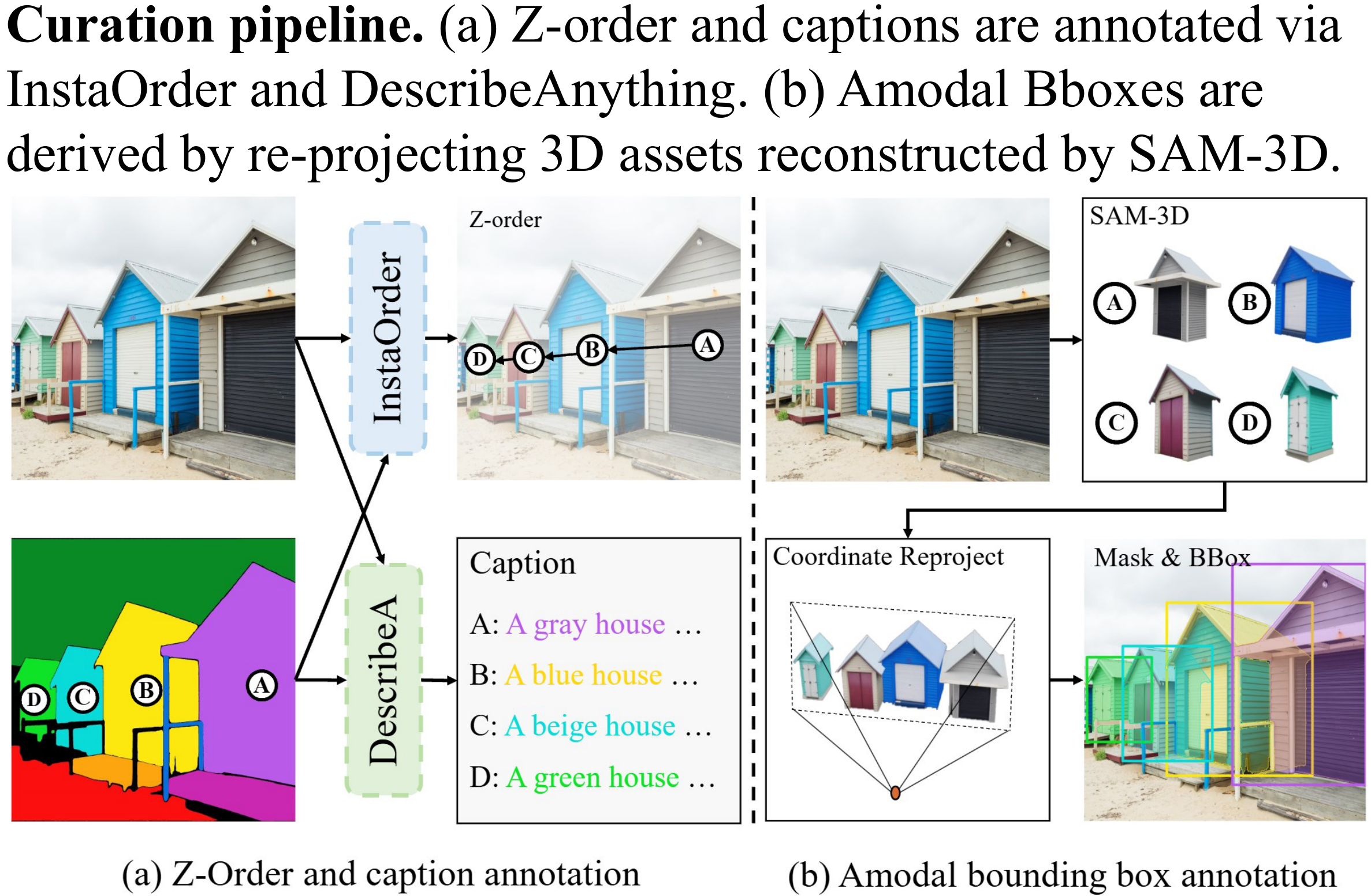
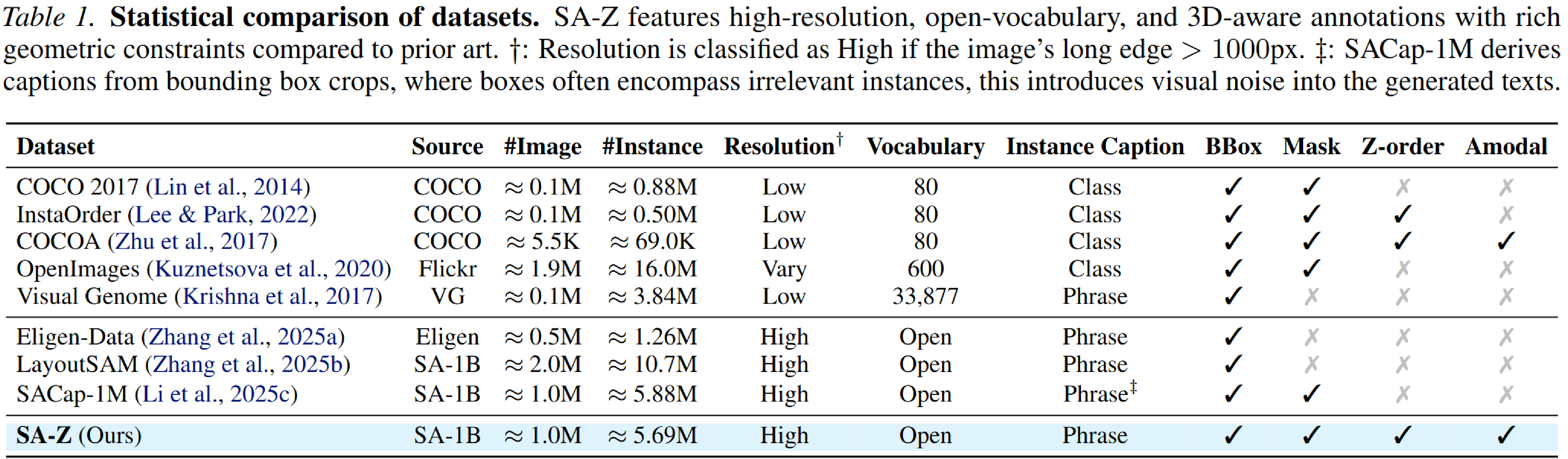
1. SA-Z Dataset
To introduce explicit occlusion supervision, we build SA-Z on top of SACap-1M, a large-scale, high-resolution dataset with 1M images and 5.7M instances. The annotation pipeline contains three key steps. First, we generate pixel-level text captions with DescribeAnything on masked regions, so each instance is described without interference from surrounding clutter. Second, we use InstaOrder to predict pairwise occlusion relations and obtain explicit Z-order annotations. Third, we rely on SAM-3D to lift each instance into 3D space and project it back to the image plane, recovering amodal bounding boxes and amodal masks. Each training sample is represented as (Mi, Bi, Oi, Ci, P), where Mi is the mask, Bi the amodal bounding box, Oi the occluding object set, Ci the instance prompt, and P the global prompt.
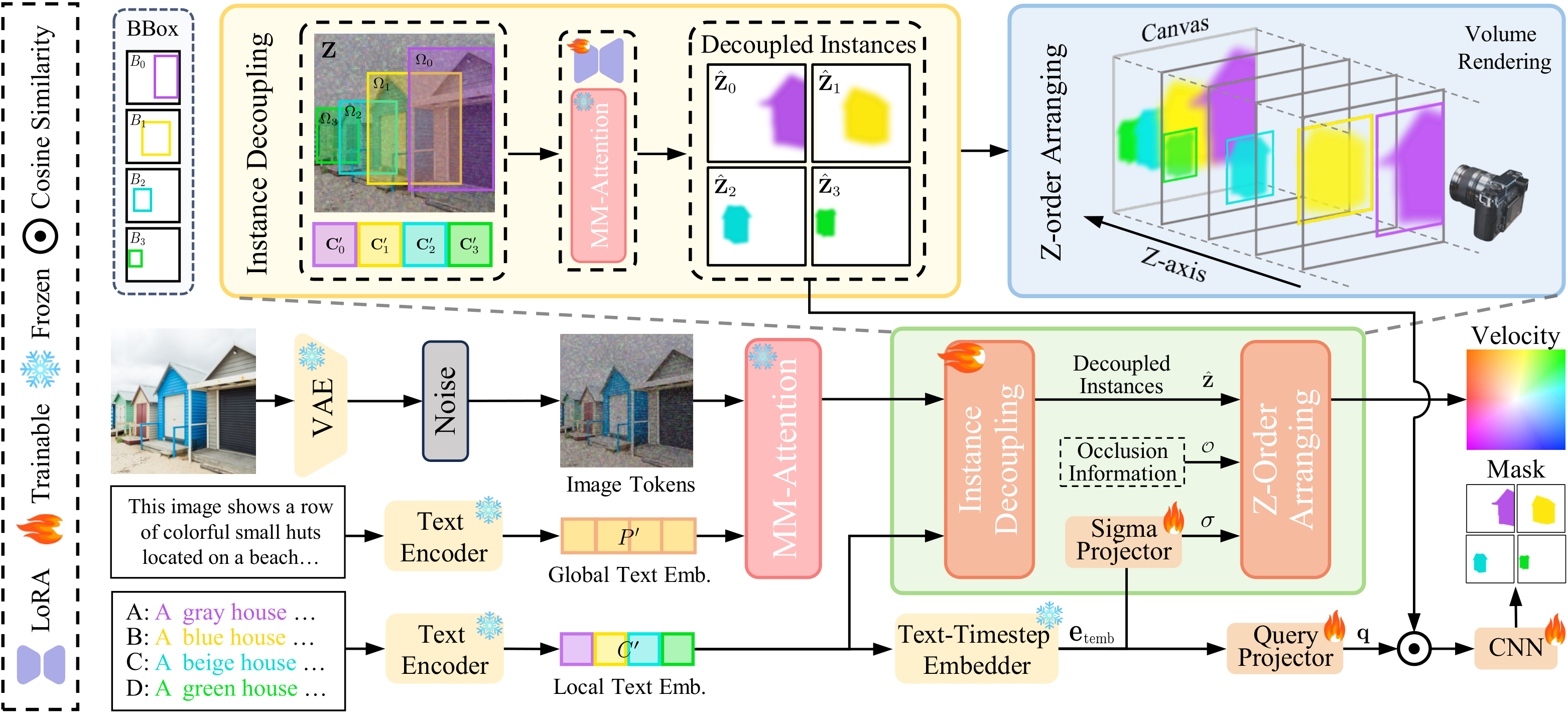
2. OcclusionFormer Core Pipeline
OcclusionFormer is an occlusion-aware Diffusion Transformer built on Flux.1-dev. Its core pipeline contains three connected stages: Instance Decoupling, Arranging the Z-order, and Queried Alignment Mechanism.
Instance Decoupling. We decouple each instance from the global layout and process instances separately, which reduces feature interference and makes occlusion reasoning more stable.
Arranging the Z-order. We predict per-instance density σ and then compose instances with volumetric rendering, so the model can generate a consistent front-to-back order in overlapped regions.
Queried Alignment Mechanism. We use ground-truth masks to supervise instance positions, which improves spatial alignment and keeps object boundaries accurate.
Experiments
We evaluate our method on OverlayBench and on ours constructed SA-Z Eval.

The visual comparison of different methods on the OverLayBench

The visual comparison of different methods on our constructed SA-Z Eval
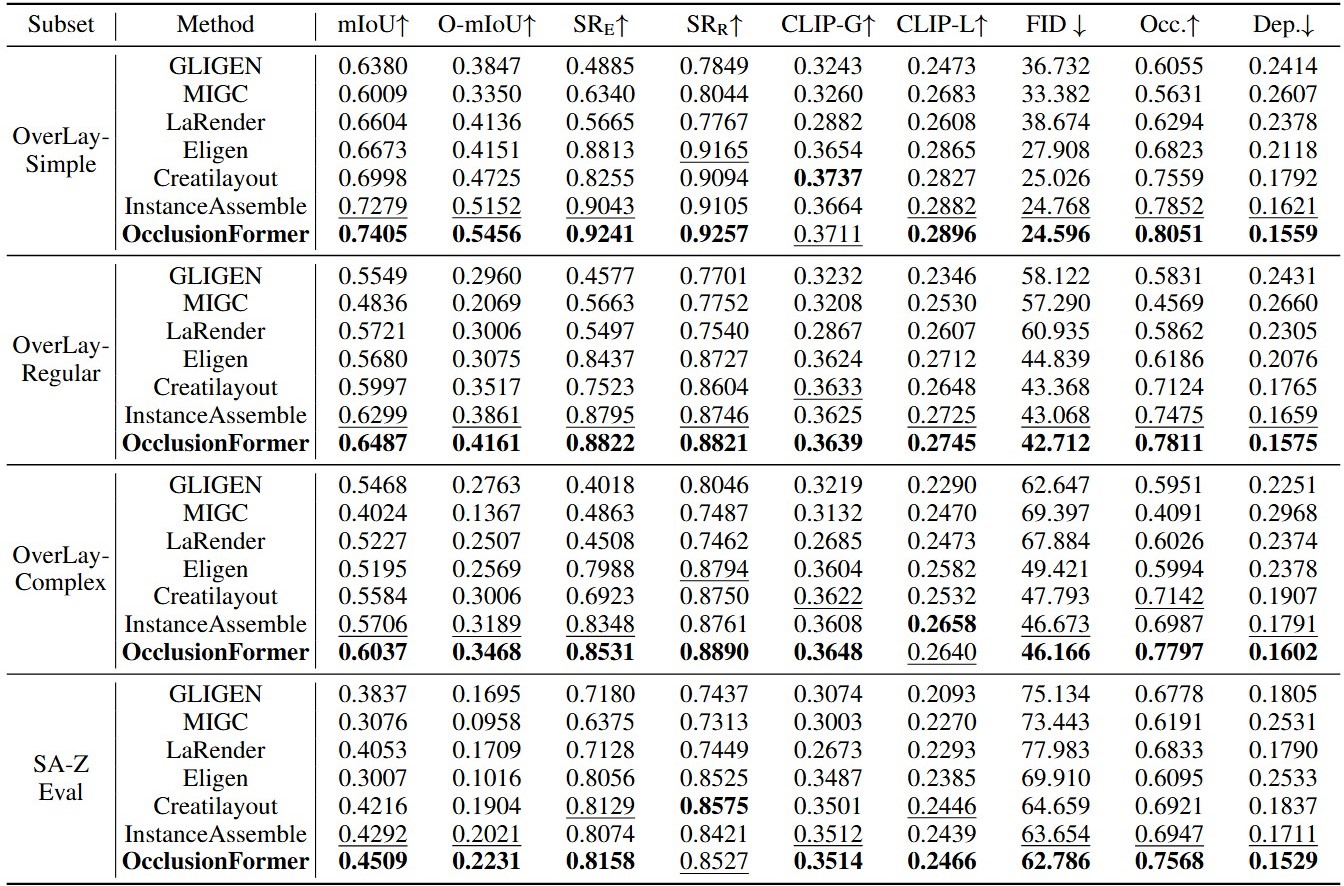
Quantitative comparison on OverlayBench and SA-Z Eval.
BibTeX
@inproceedings{li2026occlusionformer,
title={OcclusionFormer: Arranging Z-Order for Layout-Grounded Image Generation},
author={Li, Ziye and Ding, Henghui},
booktitle={ICML},
year={2026}
}